RFPose
这篇博客主要记录一下最近读到的很有趣的一篇论文“Through-Wall Human Pose Estimation Using Radio Signals”[1],这篇文章的主要工作内容是采用跨模态监督方法(cross-modal supervision)利用同步的视频和微波信号对人体姿态进行估计。
核心是基于同步采集的可标注姿态信息的视频训练不可标注的微波信号,构建跨模态的teacher-student network,将视频信号中成熟的姿态估计知识迁移到微波信号中,最终获得姿态无遮挡情况下多OKS(object keypoint similarity)标准AP(average precision)不亚于OpenPose[2]的网络模型,有遮挡情况下依然可以利用 n GHz频段的微波信号对墙后人体姿态进行估计。
阅后不瞎(own opinion)
归纳一下这篇论文获得成果的几个关键基础:
1. 物理基础
n GHz频段的电磁波可以穿透墙面,但无法穿透人体,会在人体表面发生反射
2. 数据基础
数据采集设备:webcamera(视频信号的采集),FMCW(调频连续波)+“T“形天线阵列(微波信号的采集)。其中微波信号采集的设备是以RF-Capture[3]研究作为基础并发展。
数据集构建:2000张RGB图片做标注。从50个不同场景共采集50个小时的数据,这些数据是已经同步的视觉图像和微波信号数据,平均同步误差为7ms。同一画面内人数的极值是14,平均值是1.64,也存在没有人出现的画面。为了验证模型对于穿墙场景的表现,数据集中包含一部分穿墙场景的数据,这部分数据只用来进行测试,不进行训练。同一画面内人数的极值是3,平均值是1.41。
3. 研究基础
人体姿态估计的视觉模型研究: 2D pose estimation network[2],这个网络模型也作为跨模态学习中的teacher network
跨模态迁移学习方法:设定训练目标为teacher network和student network的预测结果差异最小,损失函数定义为置信图(confidence map)中每个像素二元交叉熵损失(binary cross entropy loss)求和。整个网络架构如图所示:
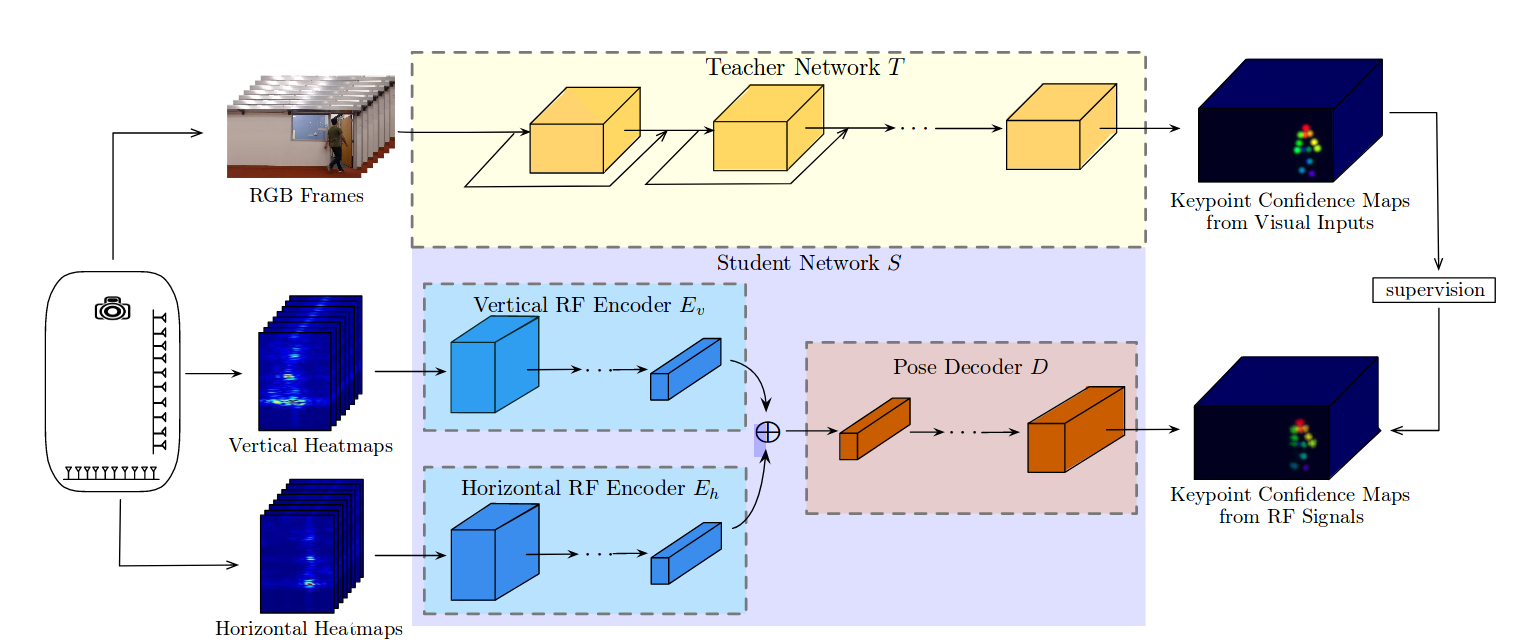
拓展理解(own opinion)
其中的teacher network已经介绍过,对于student network,输入是微波信号数据序列(单独的一帧微波数据很难获得全部的关键点提取结果,单独的一帧微波数据包含了一对水平和垂直的heatmaps),输出应该是同等帧数的关键点置信图。设计网络时考虑到使用时需要对时间和空间的偏移(translation)具有不变性,因此采用spatio-temporal convolutions[ 4,5,6]作为student network的基本构建模块(basic building blocks)。student network中包含两个编码网络分别对应水平和垂直的heatmap输入,还有一个姿态解码网络整合两个编码结果作为输入。RF encoding network使用跨步卷积网络来抵消空间维度[7,8]以整合原始信号中的信息,姿态解码网络使用分数跨步卷积网络来解码视频相机中的关键点。
网络构建和训练的具体细节
- RF encoding network
Each encoding network takes 100 frames (3.3 seconds) of RF heatmap as input. The RF encoding network uses 10 layers of 9×5×5 spatio-temporal convolutions with 1×2×2 strides on spatial dimensions every other layer. We use batch normalization [9] followed by the ReLU activation functions after every layer. - Pose decoding network
We combine spatio-temporal convolutions with fractionally strided convolutions to decode the pose. The decoding network has 4 layers of 3×6×6 with fractionally stride of 1×12×12, except the last layer has one of 1×14×14. We use Parametric ReLu [10] after each layer, except for the output layer, where we use sigmoid. - Training Details
We represent a complex-valued RF heatmap by two real-valued channels that store the real and imaginary parts. We use a batch size of 24. Our networks are implemented in PyTorch.
创新与局限
总结一下这篇论文的突破和局限:为从视觉信号出发到微波信号的迁移学习提供很好的范例。作者认为未来研究仍需要关注以下几点: 1. 不同的人之间对信号的遮挡,其他物体对信号的遮挡; 2. 微波的能量限制了可探测的距离,注意场景的约束。 3. 对人体姿态估计只考虑了站立,平稳行走的情况,对于复杂情况需要进一步探索。
参考文献
[1] Mingmin Zhao, Tianhong Li, Mohammad Abu Alsheikh, Yonglong Tian, Hang Zhao, Antonio Torralba, Dina Katabi. Through-Wall Human Pose Estimation Using Radio Signals. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2018.
[2] Cao, T. Simon, S.-E. Wei, and Y. Sheikh. Realtime multi-
person 2D pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR, 2017.
[3] F. Adib, C.-Y. Hsu, H. Mao, D. Katabi, and F. Durand. Cap-
turing the human figure through a wall. ACM Transactions on Graphics, 34(6):219, November 2015
[4] S. Ji, W. Xu, M. Yang, and K. Yu. 3D convolutional neural
networks for human action recognition. IEEE transactions on pattern analysis and machine intelligence, January 2013.
[5] D. Tran, L. Bourdev, R. Fergus, L. Torresani, and M. Paluri. Learning spatiotemporal features with 3D convolutional networks. In
Proceedings of the IEEE international conference on computer vision , ICCV, 2015.
[6] L. Wang, Y. Xiong, Z. Wang, Y. Qiao, D. Lin, X. Tang, and
L. Van Gool. Temporal segment networks: Towards good practices for deep action recognition. In ECCV , 2016.
[7] M. D. Zeiler, D. Krishnan, G. W. Taylor, and R. Fergus. De-
convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , CVPR, 2010.
[8] C. Vondrick, H. Pirsiavash, and A. Torralba. Generating
videos with scene dynamics. In Advances In Neural Information Processing Systems , NIPS, 2016.
[9] S. Ioffe and C. Szegedy. Batch normalization: Accelerating
deep network training by reducing internal covariate shift. In Proceedings of the 32nd International Conference on Machine Learning, ICML, 2015.
[10] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep into
rectifiers: Surpassing human-level performance on imagenet classification. In
Proceedings of the IEEE international conference on computer vision, ICCV, 2015.